Qué revela el mapa de 20 pipelines de Google Discover para los publishers
Análisis de 42 millones de cards (dic 2025–feb 2026) que muestra 20 pipelines, la primacía de feedads y un cascade de video EN que cambia la distribución.
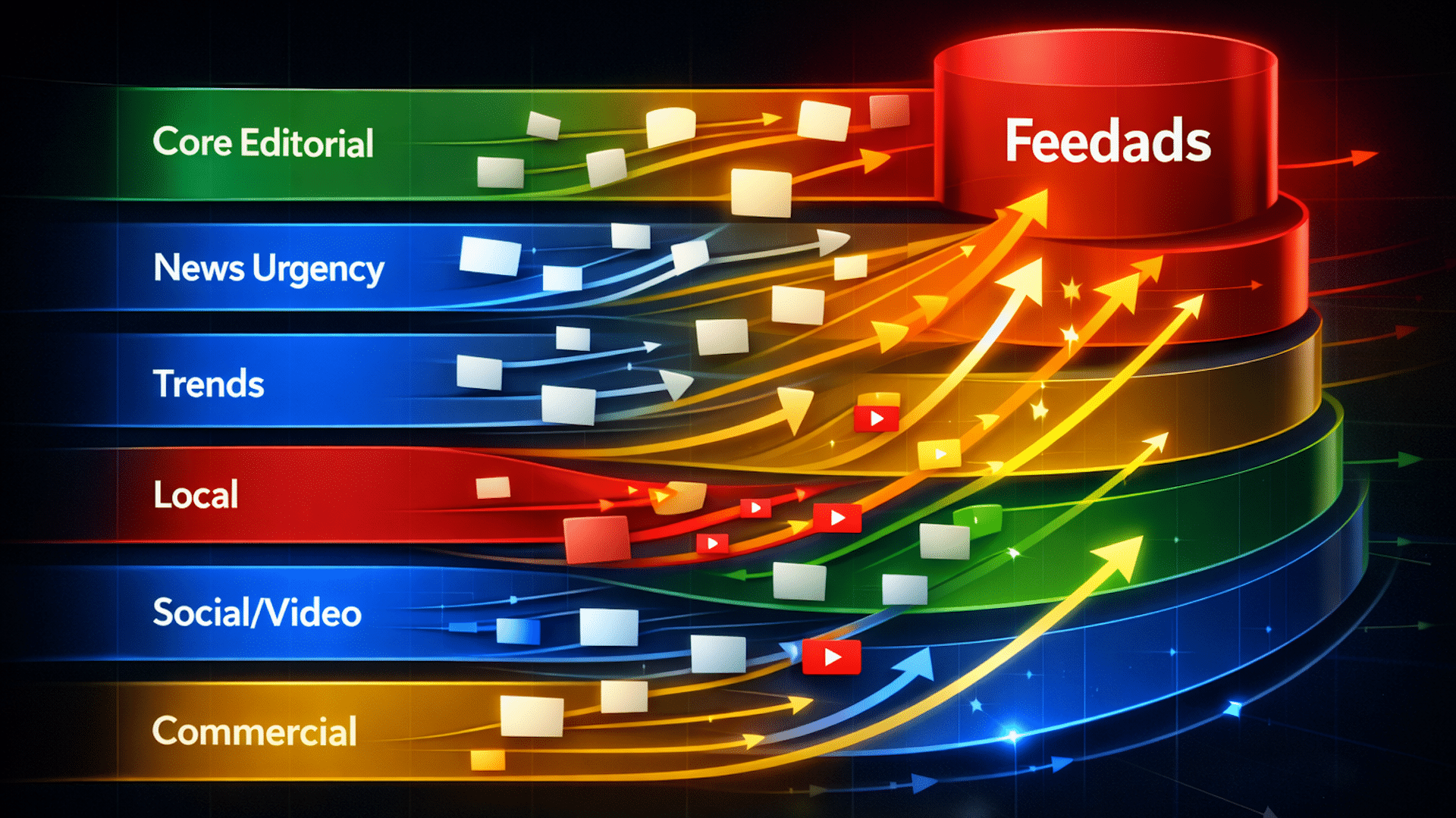
Arrancamos con el dato central: 42 millones de Discover cards, recogidas entre diciembre 2025 y febrero 2026, muestran que Google Discover no es un algoritmo único sino 20 pipelines organizados en seis capas funcionales, con un perfil de distribución muy marcado entre editorial, video y publicidad — según Search Engine Land y 1492.vision (9/4/2026).
Qué mostró el mapa y por qué importa
Vemos una arquitectura por capas: ‘content’ domina 34.2% del volumen observado en el periodo diciembre 2025–febrero 2026, mientras que ‘feedads’ alcanza 58.4% de reach en English devices en ese mismo periodo — datos de Search Engine Land / 1492.vision (9/4/2026). Eso quiere decir dos cosas: primero, la distribución editorial sigue viva pero segmentada; segundo, la monetización ocupa un espacio de reach mayor que cualquier pipeline editorial (feedads 58.4% vs neoncluster 13.0% de reach, periodo indicado por la fuente). Cada pipeline tiene lógica, velocidad y audiencia propia. No es un cajón único donde poner contenido y esperar resultados.
¿Cómo impacta esto en el mercado argentino?
No tenemos un muestreo directo para feeds en español o para Argentina en este estudio; la medición publicada cubre EN y FR entre diciembre 2025 y febrero 2026, según Search Engine Land / 1492.vision. Aun así, hay lecciones prácticas. Si feedads llega a 58.4% de dispositivos en EN y la versión francesa muestra 24% de reach por ads, observamos variabilidad por idioma y mercado. Eso implica que la presión comercial y la competencia por inventario publicitario pueden ser muy distintas localmente. Para un publisher argentino, la pregunta no es si Discover existe, sino cómo validar si su mercado muestra la misma fragmentación de pipelines, y con qué intensidad aparece la cascade de video o los AI Overviews. La respuesta pasa por medir: testeo controlado, atribución limpia y propiedad de datos propios antes de invertir a escala.
¿Qué deberían hacer los publishers argentinos?
Recomendamos tres pasos concretos. Primero, auditar: identificar cuánta de su audiencia Discover proviene de cada tipo de contenido y medirlo con una ventana de tiempo (por ejemplo, comparar diciembre 2025 vs febrero 2026 si se dispone de datos similares). Segundo, priorizar calidad editorial y readiness para AI Overviews: en EN ese pipeline representó 1.1% del volumen y estuvo dominado por medios como Reuters (12.3% del discover_ai_summary), NYT y CNBC — según Search Engine Land / 1492.vision. Tercero, asegurar propiedad y control de identidad: cookieless y walled gardens empujan a depender de señales de terceros; validar identidad y mantener attribution limpia es condición necesaria antes de escalar automatismos o IA. Si no tenemos primer party data sólido, la pauta y las decisiones creativas van a ciegas.
Pauta, video y monetización: dónde está la guita
El mapa deja claro dónde está la pauta. Feedads no solo tiene 58.4% de reach en EN; YouTube representa 53.7% de esas impresiones y las campañas median 57 días según la fuente (Search Engine Land / 1492.vision). El shopping pipeline ofrece 13.1% de reach con vida media de 2.5 días. Y la cascade de video en EN creció 18x en tres meses, con neoncluster alcanzando 13% de reach en febrero desde niveles cercanos a cero en diciembre — comparación temporal reportada por la misma investigación. Para los que buscan ROAS inmediato, esto significa competir por inventario intenso y efímero; para los que construyen marca, significa que la sobreoptimización por performance puede dejar afuera oportunidades de alcance editorial. Nuestra postura es clara: priorizar validación de identidad, atribución limpia y propiedad de datos antes de escalar inversiones en automatismos o contenidos generados por IA.

Cómo recortar gasto inútil en paid media sin romper la marca
Auditá y corregí el 20-30% del gasto que suele underperformar; priorizá identidad, atribución y propiedad de datos antes de escalar IA.

Google quita Display y Video del Performance Planner: impacto y recomendaciones
Desde marzo de 2026 Performance Planner dejó de soportar planificación para Display y Video y removió métricas de share de impresiones, empujando a anunciantes hacia métricas de conversión, según Search Engine Land.

Pronósticos de marketing: qué sirven y qué hay que cuestionar
Los forecasts convierten actividad planificada en pipeline esperado, pero requieren identidad limpia, atribución y propiedad de datos antes de automatizar con IA o vendors.